Сегодня настанет момент истины: мы напишем первое ядро нашей операционной системы atmos и запустим на нем простую многозадачную программу на Arduino!

Вот это будет простыня, ребята...
А начнем мы с того, что добавим в наш проект несколько вспомогательных файлов. Сначала напишем пару классов, чтобы можно было объявлять не-копируемые, не-перемещаемые и статические классы в C++. Класс первого типа можно будет создать и переместить, но не копировать, второго - только создать, а третьего - даже создать нельзя будет, только вызывать его статические методы. В файле noncopyable.h напишем определения первых двух классов noncopyable и nonmoveable:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
#pragma once namespace atmos { ///Базовый класс для не-копируемых классов. class noncopyable { public: noncopyable() = default; noncopyable(const noncopyable&) = delete; noncopyable& operator=(const noncopyable&) = delete; }; ///Базовый класс для не-перемещаемых классов. class nonmovable : public noncopyable { public: nonmovable() = default; nonmovable(nonmovable&&) = delete; nonmovable& operator=(nonmovable&&) = delete; }; } //namespace atmos |
В файле static_class.h определим еще один класс:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#pragma once #include "noncopyable.h" namespace atmos { ///Базовый класс для статических классов. class static_class : public nonmovable { public: static_class() = delete; }; } //namespace atmos |
Итак, если мы будем создавать новый класс, который захотим сделать не-копируемым, то будем наследовать его от базового класса noncopyable. А если, например, статическим, то от static_class.
Далее, нам потребуется класс, позволяющий отключить прерывания на какое-то время, а потом включить их обратно. Это нужно делать в тот момент, когда мы будем модифицировать некоторые критичные структуры данных ядра. Также мы будем пока что использовать отключение всех прерываний для синхронизации доступа к портам ввода-вывода со стороны процессов. Добавим в проект файл kernel_lock.h:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
#pragma once #include <stdint.h> #include <avr/interrupt.h> #include <avr/io.h> #include "noncopyable.h" namespace atmos { ///Отключает прерывания в конструкторе, ///восстанавливает их состояние в деструкторе. class kernel_lock : public nonmovable { public: kernel_lock() : prev_sreg_(SREG) { cli(); } ~kernel_lock() { SREG = prev_sreg_; } private: uint8_t prev_sreg_; }; } //namespace atmos |
Теперь при создании объекта класса kernel_lock прерывания будут отключаться, а при удалении этого объекта - включаться обратно (только если были включены на момент его создания). Этот класс является аналогом стандартного макроса ATOMIC_BLOCK из библиотеки AVR-LibC, но написанным на C++. После компиляции, кстати, код нашего класса будет занимать ровно столько же места в программной памяти, сколько и макрос на Си.
В файл defines.h я добавил пару новых макросов, которые помогут нам при создании ассемблерных вставок:
|
1 2 3 4 5 6 7 |
#ifdef __AVR_HAVE_JMP_CALL__ # define ATMOS_CALL "call " # define ATMOS_JUMP "jmp " #else //__AVR_HAVE_JMP_CALL__ # define ATMOS_CALL "rcall " # define ATMOS_JUMP "rjmp " #endif //__AVR_HAVE_JMP_CALL__ |
Если контроллер, под который собирается операционная система, поддерживает инструкции call и jmp, то макросы ATMOS_CALL и ATMOS_JUMP будут раскрываться именно в эти инструкции, а если не имеет, то в инструкции rcall и rjmp. Последние две инструкции позволяют осуществить вызов функции или переход к метке, расположенной относительно недалеко от текущей точки выполнения кода (это так называемый относительный переход, relative call/jump). Но при этом они занимают меньше программной памяти и быстрее выполняются. В контроллерах, имеющих мало программной памяти (меньше 8 Кб), нет смысла в "продвинутых" инструкциях call и jmp, потому что и без них можно перейти к любой точке адресного пространства программной памяти. В то же время, не всегда есть нужда вызывать эти самые "продвинутые" инструкции, если мы действительно не собираемся передавать управление на слишком отдаленный участок кода. У линковщика GCC есть отличная фича, позволяющая при возможности заменять call/jmp на rcall/rjmp в целях оптимизации, и мы эту фичу активировали еще в первой статье, передав линкеру и компилятору опцию -mrelax в конфигурации Release. Таким образом, на контроллерах с большим объемом программной памяти мы в ассемблере будем использовать call/jmp, но линковщик по возможности будет их заменять на rcall/rjmp.
Последний вспомогательный кусок кода, который нам понадобится - это функция offset_of, которую мы добавим в файл utils.h:
|
1 2 3 4 5 6 |
template<typename T1, typename T2> inline size_t constexpr offset_of(T1 T2::*member) { constexpr T2 object{}; return reinterpret_cast<size_t>(&(object.*member)) - reinterpret_cast<size_t>(&object); } |
Эта функция будет нам на этапе компиляции выдавать в байтах смещение от начала произвольного класса или структуры до интересующего нас поля этого класса/структуры. Зачем это потребуется, я поясню позже, а пока что приведу пример. Допустим, у нас есть следующая структура:
|
1 2 3 4 5 6 |
struct ATMOS_PACKED test { uint8_t x = 0; uint16_t y = 1; uint8_t z = 2; }; |
По смещению 0 расположено поле x размером 1 байт. Далее, по смещению 1 байт, идет поле y с размером 2 байта. Дальше, по смещению 1 + 2 = 3 байта, идет поле z. Чтобы узнать смещение поля z от начала структуры на этапе компиляции, мы сможем выполнить код offset_of(&test::z) и получить искомое значение 3. Разумеется, сама структура может быть гораздо сложнее. Она может быть унаследована от других структур (или даже иметь несколько базовых классов), в которых тоже будут какие-то поля. К сожалению, макрос offsetof (без подчеркивания) из стандартного файла stddef.h в этом случае нам не подойдет (он позволяет работать только с типами, имеющими стандартную компоновку), поэтому мы и запилили собственную функцию. У нашей функции тоже есть ограничения: тот объект, для которого будет вычисляться смещение к полю, должен иметь возможность создаваться на этапе компиляции. Таким образом, вызов функции offset_of не добавит ни байта в программный код ОС, выполнившись полностью на этапе компиляции.
Теперь, имея кучу необходимых нам инструментов, мы переходим к программированию самого ядра и обвязки для него. Определим статический класс process, в котором будут объявляться методы, типы и константы, так или иначе имеющие отношение к процессам операционной системы. Этот класс мы разместим в одноименном файле process.h. Далее я буду опускать директивы #include и объявления пространств имен, чтобы укоротить код в статье и показать только его суть.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
class process final : public static_class { public: using entry_point_type = void(*)(); #if defined(__AVR_HAVE_8BIT_SP__) || defined(__AVR_SP8__) using stack_pointer_type = uint8_t; #else //16-bit stack pointer using stack_pointer_type = uint16_t; #endif //16-bit stack pointer using id_type = uint16_t; |
Здесь мы объявляем тип точки входа (aka главной функции) для процесса ОС. Пока что это будет просто функция без аргументов, которая не возвращает никакого значения. Также мы объявили тип указателя на стек процесса. В зависимости от контроллера, он может занимать либо 1, либо 2 байта. Наконец, мы объявили тип идентификатора процесса, который в нашей ОС будет представлять из себя указатель на начало адресного пространства (блока памяти) процесса (и благодаря этому он всегда будет уникальным). Идем дальше.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
struct ATMOS_PACKED control_block { stack_pointer_type stack_pointer = 0; }; struct process_list_tag; struct process_list_element; using process_list_element_tagged = container::forward_list_element_tagged< process_list_tag, process_list_element>; struct ATMOS_PACKED process_list_element : process_list_element_tagged { control_block process; }; |
Тут мы объявляем контрольный блок процесса. Это такая структура, которая будет содержать всякую важную для процесса и ядра ОС информацию (в Windows такая тоже есть!). У нас она будет содержать пока что только указатель на вершину стека процесса. Этот указатель мы будем использовать в моменты сохранения и восстановления контекста процесса. Далее мы объявляем уже знакомый по второй статье тип списка процессов. Пока что каждый процесс у нас будет содержаться единовременно только в одном списке: списке запущенных процессов. Переходим к определению некоторых констант:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
static constexpr id_type invalid_process_id = 0u; #ifdef __AVR_3_BYTE_PC__ static constexpr size_t program_counter_size = 3; #elif defined(__AVR_2_BYTE_PC__) static constexpr size_t program_counter_size = 2; #else //__AVR_3_BYTE_PC__ static_assert(false, "Unknown program counter size"); #endif //__AVR_3_BYTE_PC__ #if __AVR_ARCH__ == 100 //avrtiny, отсутствуют регистры r0-r15 static constexpr size_t gpr_size = sizeof(uint8_t) * 16; #else //avrtiny static constexpr size_t gpr_size = sizeof(uint8_t) * 32; #endif //avrtiny static constexpr size_t sreg_size = sizeof(uint8_t); static constexpr size_t minimal_context_size = gpr_size + sreg_size + program_counter_size //адрес возврата в процесс + sizeof(process_list_element); |
Здесь у нас определяется константа, обозначающая недопустимый идентификатор процесса (0). Это идентификатор недопустим, потому что обычная оперативная память в контроллерах AVR начинается не с нулевого адреса. А идентификатор процесса, как я уже говорил, как раз и будет указателем на начало личной памяти процесса. Далее идет размер счетчика команд (зависит от устройства; на устройствах, у которых больше 128 Кб программной памяти, он занимает аж 3 байта). Этот размер указывает, сколько байтов в адресе возврата, который нам контроллер положит на стек при вызове какой-нибудь процедуры инструкцией call/rcall. Затем идет суммарный размер в байтах всех регистров общего назначения (как вы помните, в случае архитектуры avrtiny у нас таких регистров в два раза меньше), далее размер регистра SREG (всегда, конечно же, один байт). В конце мы определяем, каков должен быть минимальный размер контекста процесса. Этот размер определяет, сколько байтов памяти нам потребуется, чтобы при переключении контекста сохранить значения всех регистров общего назначения, регистра SREG, адрес возврата в процесс, а также объект process_list_element (который содержит control_block и информацию о списке, в котором процесс содержится). Меньше этого размера память процессу выдавать нельзя - будет переполнение, и наша система рухнет (возможно, не сразу, а после того, как мы получим кучу непонятных глюков).
Объявим парочку методов (один - приватный, другой - публичный) для создания процесса. Это то, чем мы будем пользоваться в нашей многопроцессной программе:
|
1 2 3 4 5 6 7 8 9 10 11 |
public: template<size_t RequiredStackSize> static id_type create(entry_point_type entry_point, process_memory_block<RequiredStackSize>& memory) { return create(entry_point, memory.get_memory(), RequiredStackSize + minimal_context_size); } private: static id_type create(entry_point_type entry_point, stack_pointer_type process_memory, size_t memory_size); |
Первый метод доступен извне, он публичный. В него мы будем передавать указатель на главную функцию (точку входа) процесса, а также память, выделенную для его работы. Здесь мы на этапе компиляции контролируем, чтобы невозможно было выделить памяти меньше, чем minimal_context_size. Вторую функцию определим в cpp-файле позже, она непосредственно будет создавать процесс в ядре нашей ОС. Шаблонный класс process_memory_block, который представляет из себя обертку над блоком памяти процесса, мы рассмотрим следующим. Его мы определим в отдельном файле process_memory.h:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
template<size_t RequiredStackSize> class ATMOS_PACKED process_memory_block { public: constexpr process_memory_block() : memory_{} { } process::stack_pointer_type get_memory() { return reinterpret_cast<process::stack_pointer_type>(memory_); } private: uint8_t memory_[RequiredStackSize + process::minimal_context_size]; }; |
Здес все просто: шаблонный параметр - это количество байтов стековой памяти, которые процессу необходимы для работы. В классе всего два метода - конструктор, инициализирующий всю память нулевыми байтами, и get_memory, возвращающий указатель на начало памяти. memory_ - это, непосредственно, блок памяти процесса. Этот блок заведомо будет иметь размер, равный и больший minimal_context_size, так что контекст процесса в нем поместится. Перед тем, как мы перейдем к написанию кода ядра, рассмотрим подробнее, что этот блок будет содержать. Я такое описание уже приводил в предыдущей статье, но там оно было неточным. Сейчас, когда мы пишем код, мы сможем корректнее и точнее определить содержимое этого блока памяти на разных этапах жизни процесса.

Из того, что поменялось, по сравнению с предыдущей статьей: теперь блок с информацией о процессе находится в начале памяти, а не в конце, а вот стек растет снизу вверх (в архитектуре avr/avrtiny стек растет от бОльших адресов к меньшим, как и в x86). На этапе (4), когда контекст процесса сохранен, указатель stack_pointer в структуре control_block указывает как раз на вершину стека. Стек может быть заполнен не до верха, потому что сам процесс может в момент прерывания не израсходовать всю стековую память, которая была для него выделена.
Напомню, что переключение процессов в нашей ОС будет осуществляться максимально просто: по прерыванию от таймера, который мы научились настраивать в первой статье цикла, мы приостанавливаем выполняемый в данный момент времени процесс и передаем управление следующему по очереди. Все процессы получат одинаковую долю процессорного времени. Пока что никакие приоритеты процессов или, тем более, динамическое планирование времени выполнения мы реализовывать не будем.
Осталась самая важная часть: код ядра. Начнем с файла kernel.h:
|
1 2 3 4 5 |
class kernel final : public static_class { public: static void ATMOS_NORETURN ATMOS_NAKED run(); }; |
И тут у нас пока что единственный метод, который запускает нашу систему. Этот метод помечен атрибутами ATMOS_NORETURN и ATMOS_NAKED. Первый означает, что метод никогда не вернет управление в вызвавшую его функцию, а второй - что метод у нас будет написан на ассемблере, и у него не будет пролога, эпилога и инструкции возврата. Т.е. это будет пустышка, код которой мы напишем сами без помощи компилятора GCC.
Ну а теперь нас ждет тяжелая артиллерия. Нужно будет написать самый первый код ядра, который будет позволять создавать процессы и переключать управление между ними по таймеру планировщика. Это все будет реализовываться в файле kernel.cpp. Что у нас этот файл будет содержать? Мы должны определить список выполняющихся процессов, а также указатель на процесс, который выполняется в данный момент времени. При создании новых процессов мы будем добавлять их в начало списка (потому что список у нас односвязный, и дешевле всего добавить новый элемент в начало такого списка). Давайте с этого и начнем:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
//Это просто укороченные имена типов из класса process. using process_list_element = atmos::process::process_list_element; using process_list_element_tagged = atmos::process::process_list_element_tagged; //Тип списка выполняющихся процессов. using process_list = atmos::container::forward_list_tagged<process_list_element_tagged>; //Выполняющийся в данный момент времени процесс. process_list_element_tagged* current_process asm("current_process") ATMOS_USED = nullptr; //Список всех процессов. process_list running_processes{}; |
Здесь все достаточно ожидаемо, кроме директивы asm("current_process") указателя current_process. Эту переменную мы будем использовать из ассемблерного кода, поэтому нам необходимо выдать ей адекватное имя, которое будет связывать эту переменную с ассемблерным кодом. C++ мог бы неким недокументированным образом переименовать этот указатель, но мы задаем строго то имя, которое хотим использовать в ассемблере. Кроме того, компилятор у меня ругался, что переменная не определена и удалял ее определение (хотя она использовалась и в коде на C++), поэтому пришлось ее явно пометить атрибутом ATMOS_USED. Далее мы перейдем к коду, создающему новый процесс:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
process::id_type process::create(process::entry_point_type entry_point, process::stack_pointer_type process_memory, size_t memory_size) { auto* process = create_process(entry_point, process_memory, memory_size); { atmos::kernel_lock lock; running_processes.push_front(process); } return to_pid(process); } |
Это объявленная ранее в файле process.h функция create, а здесь мы ее определяем. Сначала мы создаем сам процесс и получаем указатель на класс process_list_element для этого свежесозданного процесса. Затем мы, отключив прерывания, добавляем этот процесс в список всех выполняющихся процессов, а потом конвертируем указатель на process_list_element к идентификатору процесса и возвращаем его из функции. Давайте рассмотрим, что делает функция create_process:
|
1 2 3 4 5 6 7 8 |
process_list_element* create_process(atmos::process::entry_point_type entry_point, atmos::process::stack_pointer_type process_memory, size_t memory_size) { auto* elem = reinterpret_cast<process_list_element*>(process_memory); elem->process.stack_pointer = static_cast<atmos::process::stack_pointer_type>(reinterpret_cast<uint16_t>( prepare_process_context(entry_point, reinterpret_cast<uint8_t*>(process_memory) + memory_size))); return elem; } |
Мы передаем в эту функцию указатель на точку входа процесса, указатель на начало блока памяти процесса, а также размер этой памяти. Функция рассчитывает на то, что память уже проинициализирована и заполнена нулевыми байтами. Это обеспечивается тем, что пользователь будет передавать нам не сырой указатель на буфер памяти, а ссылку на шаблонный класс process_memory, определенный выше, который блок памяти и зануляет. Итак, что же здесь происходит? Мы преобразуем переданный нам указатель на память к указателю на класс process_list_element. Это не очень легальная операция, потому что у данного класса могут быть конструкторы, которые как-то хитро его инициализируют. Но сейчас в нем нет ничего, кроме указателя на следующий элемент списка и указателя на вершину стека процесса, поэтому нам не нужна какая-то особая инициализация. Поэтому вызов конструктора класса можно опустить. Далее мы подготавливаем начальный контекст для процесса, вызывая функцию prepare_process_context. Эта функция вернет нам указатель на вершину стека после заполнения контекста, и это значение мы записываем в переменную stack_pointer контрольного блока процесса. Переходим к функции prepare_process_context:
|
1 2 3 4 5 6 7 8 |
uint8_t* prepare_process_context(atmos::process::entry_point_type entry_point, uint8_t* stack_bottom) { stack_bottom = push_function_address(reinterpret_cast<const void*>(entry_point), stack_bottom); --stack_bottom; *--stack_bottom = _BV(ATMOS_AVR_INTERRUPT_BIT); stack_bottom -= (atmos::process::gpr_size - 1); return --stack_bottom; } |
Сначала мы записываем адрес главной функции процесса (entry_point) на самое дно стека (т.е. в самый низ блока памяти процесса). Это будет адрес возврата, на которое ядро будет передавать управление после восстановления контекста. Далее начинается контекст процесса. Изначально в нем все регистры будут равны нулю, а в регистре SREG будет установлен единственный бит, включающий прерывания для процесса. Таким образом, для всех свежесозданных процессов прерывания по умолчанию будут включены. Мы перемещаем указатель стека на один байт вверх (--stack_bottom). Это ячейка, в которой размещается регистр R31. Память уже заполнена нулями, поэтому нет необходимости еще раз записывать в эту ячейку (как и во все другие) нулевое значение. Далее в нашем контексте всегда идет SREG, и туда мы записываем значение _BV(ATMOS_AVR_INTERRUPT_BIT). Это, по сути, значение 1 << ATMOS_AVR_INTERRUPT_BIT, которое равно 0b10000000 в двоичной системе. Все биты установлены в ноль, а бит, отвечающий за прерывания, - в единицу. Далее мы уменьшаем стековый указатель на то количество регистров общего назначения, которое есть в контроллере (gpr_size) минус единица (потому что первый регистр, R31, уже получил свой байт). Наконец, мы возвращаем из функции указатель на вершину стека. Здесь помимо прочего используется функция push_function_address:
|
1 2 3 4 5 6 7 8 9 10 |
uint8_t* push_function_address(const void* address, uint8_t* stack_bottom) { *--stack_bottom = static_cast<uint8_t>(reinterpret_cast<uint16_t>(address)); *--stack_bottom = static_cast<uint8_t>(reinterpret_cast<uint16_t>(address) >> 8); #ifdef __AVR_3_BYTE_PC__ --stack_bottom; #endif //__AVR_3_BYTE_PC__ return stack_bottom; } |
Она не делает ничего особенного, кроме как записывает на стек указатель на главную функцию (точку входа) процесса. Этот указатель в большинстве случаев имеет размер два байта, но в некоторых случаях, когда программной памяти у контроллера больше, чем 128 Кб (это как раз случай Arduino Mega 2560), этот указатель может занимать три байта. GCC не поддерживает вызовы функций по длинным указателям, да и трехбайтные указатели в целом тоже, но нам нужно все равно зарезервировать один дополнительный байт на стеке, потому что инструкция ret/reti, которую мы используем для возврата в код процесса из ядра (как описано в предыдущей статье), будет считывать со стека именно три байта для таких контроллеров. Нам осталось рассмотреть только функцию to_pid:
|
1 2 3 4 5 6 7 |
template<typename ListElement> atmos::process::id_type to_pid(ListElement* elem) { static_assert(sizeof(process_list_element*) == sizeof(atmos::process::id_type), "Unsupported pointer type size"); return reinterpret_cast<atmos::process::id_type>(static_cast<process_list_element*>(elem)); } |
Это простая функция, которая конвертирует указатель на элемент списка процесса (process_list_element) в тип идентификатора процесса, предварительно на этапе компиляции проверяя, что размеры этих типов совпадают, и такое преобразование возможно.
Нам осталось запилить функционал, который будет:
- Сохранять контекст процесса.
- Загружать контекст процесса и передавать этому процессу управление.
- Выбирать, какой из процессов будет выполняться следующим.
Начнем мы с функции сохранения контекста. Эта функция будет сохранять контекст на стеке текущего процесса, сохранять в переменной stack_pointer контрольного блока процесса указатель на вершину его стека, а потом вызывать функцию, которая выполнит переход к другому процессу и восстановит его контекст.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
void ATMOS_HOT ATMOS_NAKED ATMOS_USED save_context_and_switch_to_next_process_func() asm("save_context_and_switch_to_next_process_func"); #define save_context_and_switch_to_next_process() \ __asm__ __volatile__ (ATMOS_JUMP "save_context_and_switch_to_next_process_func" ::: "memory") void save_context_and_switch_to_next_process_func() { save_r31_and_sreg_from_scheduler(); save_context_except_r31_and_sreg(); __asm__ __volatile__ ( "in r28, __SP_L__ \n\t" #if !defined(__AVR_HAVE_8BIT_SP__) && !defined(__AVR_SP8__) "in r29, __SP_H__ \n\t" #endif //16-bit stack #if __AVR_ARCH__ == ATMOS_AVRTINY_ARCH_ID "ldi r30, lo8(current_process) \n\t" "ldi r31, hi8(current_process) \n\t" "ld r26, Z+ \n\t" "ld r27, Z \n\t" "subi r26, lo8(-(%0 + 1)) \n\t" "sbci r27, hi8(-(%0 + 1)) \n\t" # if !defined(__AVR_HAVE_8BIT_SP__) && !defined(__AVR_SP8__) "st X, r29 \n\t" # endif //16-bit stack "st -X, r28 \n\t" #else //not avrtiny "lds r30, current_process \n\t" "lds r31, current_process + 1 \n\t" # if !defined(__AVR_HAVE_8BIT_SP__) && !defined(__AVR_SP8__) "std Z + %0 + 1, r29 \n\t" # endif //16-bit stack "std Z + %0, r28 \n\t" #endif //avrtiny :: "M" (offset_of(&atmos::process::process_list_element::process) + offset_of(&decltype(atmos::process::process_list_element::process)::stack_pointer)) ); switch_to_next_process_context(); } |
Да, вот так вот сразу по-хардкору! Сначала объявляем функцию save_context_and_switch_to_next_process_func, чтобы задать ей определенные атрибуты: hot, naked, used (горячая, обнаженная и попользованная, мммм, на самом деле: часто вызываемая, без пролога и эпилога и используемая в коде). Также мы задаем для функции имя, которое будет видно в ассемблерном коде. Далее идет макрос save_context_and_switch_to_next_process, который является просто переходом (jmp) на эту функцию. Мы не можем ее вызывать классическим способом, потому что это испортит наш стек, ведь контроллер в этом случае на стек положит адрес возврата. Мы можем только "перепрыгнуть" на ее тело, чтобы стековый указатель SP не изменился, и ничего на стеке не перетерлось. Поэтому вместо save_context_and_switch_to_next_process_func() для вызова этой функции мы будем писать save_context_and_switch_to_next_process(). Кроме того, макрос save_context_and_switch_to_next_process содержит барьер памяти (увидели там "memory"?). Эта шняга нужна для того, чтобы сказать компилятору: мы сейчас будем творить безобразие (а именно, переключим контекст процесса), поэтому давай прямо сейчас из временных регистров быстро запиши все данные в память. Если у компилятора на момент вызова хранились в некоторых регистрах какие-то данные, которые он планировал перенести в ячейки оперативной памяти, то он их перенесет сиюминутно перед непосредственно выполнением макроса. В противном случае эти регистры мы можем затереть, сменить стековый указатель, и компилятору уже поздно будет что-либо делать, все полетит к чертям.
Переходим к содержимому функции. Сначала сохраняем полностью контекст процесса. Все интересующие нас регистры. А вот дальше нам нужно как-то сохранить в контрольном блоке процесса указатель на вершину стека, который сейчас записан в регистре SP. Мы могли бы просто написать следующую строку кода:
|
1 |
(*current_process)->process.stack_pointer = SP; |
... и дело сделано! Но, к сожалению, этого мы делать не можем будем. Документация на AVR-GCC в описании атрибута функции naked явно указывает на то, что мы не имеем права в таких вот функциях без пролога и эпилога использовать код на Си или C++. Работоспособность такого кода в naked-функциях не гарантируется. Конечно, мы могли бы обернуть эту строку кода в отдельную, классическую, функцию и вызвать ее из этой, но, черт возьми, после сохранения контекста у нас на стеке процесса может не быть свободного места, и контроллеру негде будет сохранить адрес возврата. Можно выгрузить часть контекста снова в регистры, которые GCC использовать не будет, но это слишком большая лишняя работа в данном случае. Поэтому эту строку кода нам будет оптимальнее всего написать сразу на ассемблере. Тут появляются всякие нюансы. Поле stack_pointer структуры process (которая имеет тип control_block) находится на определенном смещении от начала этой структуры. Точно так же, сама структура process, содержащаяся в структуре process_list_element находится на каком-то смещении от начала этой структуры. Эти смещения нам надо как-то вычислить, чтобы добраться до интересующего нас поля. Для этого мы будем использовать написанную ранее функцию offset_of, которая произведет нужные вычисления на этапе компиляции. Затем мы, используя связку "M", пробросим сумму этих смещений в ассемблерный код. Таким образом, в ассемблере мы будем знать, на каком смещении от начала структуры process_list_element расположено интересующее нас поле stack_pointer.
В самой же ассемблерной вставке мы записываем в регистры R28 и R29 значение стекового указателя. В контроллерах с малым объемом оперативной памяти регистра SPH (старшая часть стекового регистра) может и не быть, это мы тоже учли. Далее у нас два варианта кода: для архитектуры avrtiny и для всех остальных. Для avrtiny мы сначала считываем в регистр Z (который, как вы помните из предыдущих статей, состоит из двух восьмибитных регистров R31:R30) указатель на ячейки оперативной памяти, в которой лежит указатель на структуру текущего процесса. Затем мы с помощью инструкции ld этот указатель разыменовываем. Теперь у нас в регистрах R27:R26 (они же - регистр X) лежит указатель на структуру process_list_element текущего процесса. Далее мы прибавляем к этому указателю вычисленное смещение к полю stack_pointer. Делается это двумя инструкциями subi и sbci, которые выполняют вычитание и вычитание с переносом, соответственно. Почему вычитание? Потому что в AVR отсутствует инструкция сложения регистра с числом, да. Сложить регистр с другим регистром можно, а вот регистр с числом - нет. Поэтому мы вычитаем отрицательные смещения, а минус на минус дает плюс, так оптимальнее и по скорости, и по размеру получающегося кода. Наконец, с помощью команды st мы записываем по этому указателю X (который теперь указывает на поле stack_pointeravr код несколько проще, потому что они имеют продвинутую инструкцию lds. Она за нас разыменовывает указатель на ячейку памяти, где лежит указатель на текущий процесс, и его-то мы на блюдечке и получаем в регистре Z. Остается с помощью другой продвинутой инструкции std записать в него стековый указатель.
Вот и все. Далее вызываем макрос switch_to_next_process_context (который развернется в ассемблерную вставку), чтобы перейти к контексту следующего на очереди процесса, восстановить его контекст и приступить к исполнению.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
void ATMOS_HOT ATMOS_NAKED ATMOS_USED switch_to_next_process_context_func() asm("switch_to_next_process_context_func"); #define switch_to_next_process_context() __asm__ __volatile__ \ (ATMOS_JUMP "switch_to_next_process_context_func" ::: "memory") void switch_to_next_process_context_func() { __asm__ __volatile__ ( "pop r28 \n\t" "pop r29 \n\t" #ifdef __AVR_3_BYTE_PC__ "pop r2 \n\t" #endif //__AVR_3_BYTE_PC__ ATMOS_CALL "choose_next_process \n\t" #ifdef __AVR_3_BYTE_PC__ "push r2 \n\t" #endif //__AVR_3_BYTE_PC__ "push r29 \n\t" "push r28 \n\t" #if !defined(__AVR_HAVE_8BIT_SP__) && !defined(__AVR_SP8__) "out __SP_H__, r25 \n\t" #endif //16-bit stack "out __SP_L__, r24 \n\t" :: ); restore_context_except_r31_and_sreg(); restore_r31_and_sreg_and_switch_context(); } |
Здесь вы видите уже знакомое объявление функции с атрибутами, такой же макрос, производящий переход на тело функции и содержащий барьер памяти. Перейдем сразу к ассемблерной вставке. Нам, по сути, тут уже пора выбрать, какой же процесс будет выполняться следующим. Но на данном этапе выполнения у нас контексты всех процессов сохранены, поэтому места в оперативной памяти для ядра как бы и нет. Мы не можем воспользоваться пространством стека процесса, потому что мы только что начинили его контекстом процесса, и места там больше нет. Но осуществлять выбор следующего на выполнение процесса - это не одна строка кода на C++, а в перспективе, если мы вдруг решим добавить приоритеты задач или еще чего похлеще, их будет даже и не один десяток. Но вы уже по предыдущей функции запомнили, что даже одна строка кода C/C++, переведенная в ассемблер, может быть болью и унижением. Поэтому тут я все же решил вынести код в отдельную классическую (не-naked) функцию и вызвать ее из этой ассемблерной вставки.
Но вот незадача: если мы выполним инструкцию call/rcall, то контроллер нам на стек по текущему стековому указателю положит адрес возврата, чтобы потом мы вернулись на место вызова, когда функция, которую мы вызвали, выполнит инструкцию ret. А стек-то у нас уже забит! Придется его слегка освободить. Регистры-то свободны все, мы их только что сохранили в контекст процесса. Вот и освободим из контекста два или три байта (три - если у контроллера более 128 Кб программной памяти), поместив данные со стека в регистры R28, R29 и, при необходимости R2. Почему именно в эти? Потому что по конвенции вызовов AVR GCC, эти регистры все функции не трогают, а если и трогают, то после вызова восстанавливают их значения на те, которые были в них записаны на момент вызова. Окей, сохранили, потом вызываем choose_next_process, которая нам выберет следующий по очереди процесс на выполнение и вернет указатель на вершину стека процесса. Далее мы запихиваем эти злосчастные три байта из R28, R29 и R2 обратно в стек, а потом двумя инструкциями out перезаписываем стековый указатель. Вот он - момент истины: после выполнения этих двух инструкций мы уже находимся в контексте следующего процесса, которому пора выполняться! Поэтому все, что остается сделать, - это восстановить его контекст и передать ему управление, что мы и делаем, вызвав два соответствующих макроса.
Думаете, легко отделались? А вот и нет, еще рано радоваться. Что, если функция choose_next_process захочет что-то разместить на стеке? Что, если ей регистров будет мало? Тогда у нас все будет плохо: мы освободили пару-тройку байтов под адрес возврата, а вот для самой функции у нас на стеке процесса места совсем не осталось. GCC достаточно умный компилятор, и стек старается использовать только тогда, когда уже совсем прижало, но надо бы как-то проконтролировать, что функция туда все же не лезет. К счастью, способ это сделать нашелся. Для файла kernel.cpp в опциях сборки для всех конфигураций мы напишем следующее:
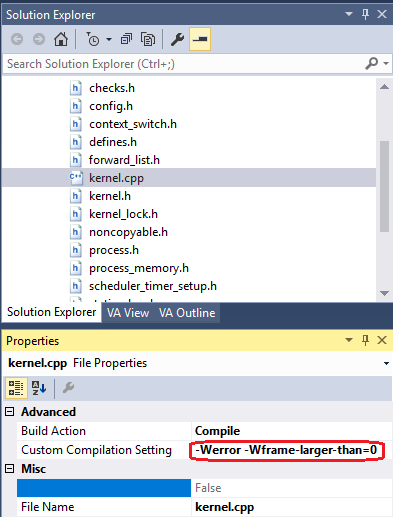
Эти опции сообщат компилятору, что надо обрывать сборку с ошибкой, если вдруг какая-то из функций в файле жрет стекового пространства больше, чем 0 байтов. Это, конечно, очень строго, предъявлять такое требование ко всем функциям, но подобную опцию применить к единственной функции, к сожалению, нельзя. Зато можно уже в коде файла kernel.cpp отключить ее для всего кода, кроме требуемого. Это мы и сделаем. Функцию choose_next_process мы разместим в самом начале файла, а после нее разместим директиву GCC, которая отключит эту опцию для того кода, который идет ниже.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
atmos::process::stack_pointer_type ATMOS_HOT ATMOS_USED choose_next_process() asm("choose_next_process"); atmos::process::stack_pointer_type choose_next_process() { process_list_element_tagged* current = current_process; auto* first = running_processes.first(); if(!current) { current = first; } else { current = process_list::next(current); if(!current) current = first; } current_process = current; return (*current)->process.stack_pointer; } //Вот эта директива: #pragma GCC diagnostic ignored "-Wframe-larger-than=" |
А что же с самой функцией? Ее уже можно вызывать, как совершенно обычную. У нее есть пролог, эпилог и инструкция возврата, потому что мы ей не задали атрибут ATMOS_NAKED, как у двух предыдущих функций. И код мы, соответственно, можем совершенно легально писать на C/C++. Мы берем значение переменной current_process и вызываем метод process_list::next, который вернет тот процесс, который идет в списке за текущим. Однако, если он нулевой (т.е. текущий процесс был последним в списке), то мы просто берем первый процесс в списке. Если же значение current_process нулевое, это значит, что ОС только что запустилась, и нам просто нужно взять самый первый процесс из списка. Наконец, мы присваиваем переменной current_process указатель на этот самый процесс, который будем выполнять, и возвращаем из функции указатель на его стек, чтобы дальше ассемблерный код восстановил его контекст и передал ему управление. По конвенции вызовов AVR GCC возвращаемое значение размером два байта будет размещено в регистрах R25 и R24, этим мы и пользуемся, копируя значения этих регистров в регистры SPH и SPL в ассемблерной вставке из предыдущего листинга.
Вооот. Теперь мы закончили. Сомневаюсь, конечно, что до этого места кто-то дочитал и сохранил спокойствие, но нужно же закончить повествование. Проверим нашу операционку! Откроем файл main.cpp и напишем следующий код:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#include <avr/io.h> #include <stdint.h> #include <util/delay.h> #include "kernel/defines.h" #include "kernel/kernel.h" #include "kernel/kernel_lock.h" #include "kernel/process.h" #include "kernel/process_memory.h" using namespace atmos; namespace { process_memory_block<8> process1_memory; process_memory_block<8> process2_memory; process_memory_block<8> process3_memory; void ATMOS_OS_TASK process1(); void ATMOS_OS_TASK process2(); void ATMOS_OS_TASK process3(); |
Тут мы подключаем все необходимые файлы. Далее объявляется три области памяти для трех процессов, и объявляются главные функции этих трех процессов. Для каждого из процессов мы выделили по 8 байтов стека (потом расскажу, как можно определять размер требуемого стека более точно, но этого нам сейчас должно хватить). Каждый из процессов мы пометили атрибутом ATMOS_OS_TASK. Этот атрибут говорит компилятору GCC, что у функции, по сути, свой собственный набор регистров, и функция не обязана сохранять те регистры, которые обычно сохраняются по соответствующей конвенции вызовов. Этот атрибут необязателен, но сэкономит нам память, как программную, так и оперативную.
Что же будут делать наши процессы? Пускай сначала запускается только первый, моргает светодиодом несколько раз, а потом запускает второй и третий процессы, которые будут моргать другими светодиодами, и каждый - со своим интервалом.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
void process1() { uint8_t i = 20; while(true) { if(i && !--i) { process::create(process2, process2_memory); process::create(process3, process3_memory); } _delay_ms(100); kernel_lock lock; PORTC ^= _BV(PC0); } } void process2() { while(true) { _delay_ms(300); kernel_lock lock; PORTC ^= _BV(PC1); } } void process3() { while(true) { _delay_ms(1000); kernel_lock lock; PORTC ^= _BV(PC2); } } } //namespace |
Для задержки между включением-выключением светодиодов мы будем использовать функцию _delay_ms, встроенную в AVR-LibC и определенную в файле <util/delay.h>. Величина задержки ей передается в миллисекундах. Таким образом, первый процесс будет моргать светодиодом 10 раз в секунду, второй - раз в треть секунды, а третий - раз в секунду. Когда мы меняем состояние порта ввода-вывода операцией ^=, мы отключаем прерывания, создавая объект типа kernel_lock. Это нужно для того, чтобы сохранить атомарность операции работы с портом ввода-вывода. Ведь ^= - это на самом деле чтение значения порта, затем применение битовой операции "исключающее или" к полученному значению (чтобы изменить его на противоположное), затем запись значения обратно. Если ОС прервет процесс в момент, когда тот считал значение порта, но еще не записал его обратно, а другой процесс в этот момент изменит значение какого-нибудь бита в том же самом порте, то у первого процесса значение окажется неактуальным. Поэтому и нужно отключать прерывания на момент чтения-записи значения порта. Осталось написать код функции main:
|
1 2 3 4 5 6 |
int main() { DDRC |= _BV(PC0) | _BV(PC1) | _BV(PC2); process::create(process1, process1_memory); kernel::run(); } |
Здесь мы устанавливаем пины PC0, PC1 и PC2 в режим выхода (output), записывая соответствующую битовую маску в управляющий регистр DDRC, затем создаем процесс process1 и запускаем ядро нашей операционной системы.
Давайте перед запуском кода все-таки определим, сколько же стека хотя бы примерно потребуется нашим процессам. Самым простым, конечно, будет просто поделить всю доступную оперативную память между этими тремя процессами (тем более новых процессов мы не создаем, а старые не завершаем). Однако, в GCC есть опция -fstack-usage, которая поможет нам в более точном определении потребностей процесса. Давайте зададим эту опцию компиляции для файла main.cpp. После сборки проекта (я собирал для ATmega 2560) в папке соответствующей конфигурации (Release/Debug) появится файл main.su. Откроем его и увидим следующий отчет:
|
1 2 3 4 |
main.cpp:51:6:void {anonymous}::process3() 3 static main.cpp:41:6:void {anonymous}::process2() 3 static main.cpp:24:6:void {anonymous}::process1() 3 static main.cpp:62:5:int main() 3 static |
Мы видим, что каждый из процессов требует по три байта. По сути, эти три байта мы уже учли - это размер того самого адреса возврата, который у нас лежит в контексте процесса. Поэтому можно считать, что каждая из функций не требует стека вообще. Пометка static обозначает, что потребление стековой памяти у функции сугубо статично, и внезапно больше, чем тут указано, она занять не может никак. Но функция process1 вызывает другую функцию - atmos::process::create. А это значит, что нам нужно проанализировать и то, сколько стека использует эта функция. Мы можем точно так же передать компилятору опцию -fstack-usage для файла kernel.cpp, но компилятор заругается с сообщением, что не все функции можно скомпилировать с такой опцией. Оно и понятно: мы нафигачили гору ассемблерных вставок, об использовании стека которыми компилятор Си/C++ никак узнать не может. Можно, конечно, на время убрать из опций компиляции -Werror, которую мы добавили раньше, и получить интересующий нас отчет:
|
1 2 |
kernel.cpp:39:36:atmos::process::stack_pointer_type {anonymous}::choose_next_process() 3 static kernel.cpp:224:18:static atmos::process::id_type atmos::process::create(atmos::process::entry_point_type, atmos::process::stack_pointer_type, size_t) 3 static |
Снова три байта! То, что в отчете отсутствуют другие функции, говорит либо о том, что функция не поддерживается (содержит ассемблерные вставки), либо о том, что она заинлайнилась (т.е, ее тело встроилось полностью внутрь тела другой функции). Так как atmos::process::create не вызывает функций с ассемблерными вставками, это значит, что все те функции, которые она вызывает, были в ее тело встроены компилятором с целью оптимизации. Так оно и есть: в этом можно убедиться, открыв ассемблерный листинг функции, который можно найти в файле kernel.lst или atmos.lss. Кстати, есть ведь и другой способ оценить, сколько стековой памяти использует та или иная функция. В файле, например, kernel.lst, найдя код интересующей нас функции, можно увидеть объявление символа __stack_usage:
|
1 2 3 4 5 6 7 8 9 10 |
223:../kernel/kernel.cpp **** //Creates new process. 224:../kernel/kernel.cpp **** process::id_type process::create(process::entry_point_type entry_point, 225:../kernel/kernel.cpp **** process::stack_pointer_type process_memory, size_t memory_size) 226:../kernel/kernel.cpp **** { 409 .LM26: 410 .LFBB6: 411 /* prologue: function */ 412 /* frame size = 0 */ 413 /* stack size = 0 */ 414 .L__stack_usage = 0 |
Здесь мы явно видим, что __stack_usage = 0. Это значит, что функция не требует стековой памяти. Но для ее вызова, разумеется, нужны те три байта, о которых нам докладывала опция компилятора -fstack-usage. Ведь контроллер при вызове функции будет автоматически на стек записывать ее адрес возврата, а на это нужно место.
Как бы то ни было, восьми байтов каждому из процессов должно хватить. В профессиональных ОС под AVR существуют определенные методы контроля переполнения стека (которые, впрочем, гарантировать 100% результат не могут). Нет, в AVR, конечно же, отсутствуют атрибуты доступа к памяти, как в x86, поэтому и методы эти просты как пробка. Работают они примерно так: в памяти процесса выделяется на один байт памяти больше. Этот байт инициализируется некоторым случайным или конкретным значением (его можно называть Guard byte). В момент переключения контекста с одного процесса на другой ОС проверяет, не перетерто ли значение этого байта каким-то другим. Если так, то дело плохо - тот процесс, с которого мы переключаемся, в процессе своей работы переполнил стек. Далее продолжать работу ОС становится бессмысленно, потому что могут оказаться попорченными не только тот байт, но и другие, следующие за ним, и ОС просто рапортует доступными средствами о крахе и зависает в бесконечном цикле.
Компилируем код (в конфигурации Release он у меня занимает всего 664 байта программной и 148 байтов оперативной памяти) и прошиваем его в нашу Arduino Mega 2560. Кстати, для Arduino Uno r3, в которой контроллер попроще, ATmega328P, проект после компиляции занимает всего 532 байта программной памяти и 145 байтов оперативы. Подключаем к пинам контроллера PC0, PC1 и PC2 (которым соответствуют выводы 37, 36 и 35 на Arduino Mega 2560) светодиоды через небольшие сопротивления, как делали в первой статье, и поехали!
После просмотра видео у вас, наверное, возникнет вопрос: почему сначала, когда активен только первый процесс (process1), светодиод моргает быстро, а когда запускаются два дополнительных процесса, то он начинает моргать медленно? Да и светодиоды, которыми управляют два других процесса, моргают не с той частотой, которую мы задали (раз в треть секунды/раз в секунду), а раза в три медленнее? Дело все в том, что процессорное время делится между тремя процессами поровну. Каждый из них получает свою честную треть. В итоге, если усреднить, получается, что каждый из процессов выполняется с частотой 16МГц/3. А это значит, что и функция _delay_ms, которая внутри себя имеет просто цикл на определенное количество итераций, будет выполняться в три раза медленнее. В конечно счете каждый из процессов будет моргать своим светодиодом в три раза медленнее, чем мы планировали. С этим можно справиться, если придумать и запрограммировать системный метод sleep, который будет по-настоящему прерывать выполнение процесса на заданный промежуток времени, отдавая появившийся на это время ресурс выполнения другим процессам, которые в этот момент не спят. Этим мы и займемся в следующей статье.
А пока что, как всегда, можно следить за развитием проекта на GitHub, а скачать солюшен к статье можно по этой ссылке: Atmos solution.
А нельзя ли ядро вынести в отдельный процесс, в который переключать контекст всегда по любому прерыванию, после чего этот процесс делает что хочет, но может вызвать функцию, которая сбросит переключит его на другой процесс, сбросив адрес возврата на начало функции?
Пока нет смысла в том, чтобы ядро было в виде отдельного процесса. Ядру не нужно хранить состояние регистров и не нужен (пока что) собственный стек. Весь стейт ядра хранится глобально, потому что ядро в системе всего одно.
Смотрю я на то где, как и кем используются RTOS
И пришел к выводу, что для простеньких контроллеров в 99% все сводится к статическому объявлению 3х-5и задач(потоков), при этом все они уникальные, и запускаются все на ранней стадии.
Ну так почему ж по-прежнему держимся за класический подход - нужно создать описатель задачи глобально (включаяя выделение памяти под стек, контекст), и в мейне вызвать create_task?...
Раз уж все задачи известны, расписаны и объявлены, почему б ядро не слинковать со всеми ими статически - тут и аллокацию ивентов, очередей, мьютексов... Всё можно слинковать статически, оптимизировать менеджмент... Даже избавиться от двунаправленного списка, заменив его на массив индексов...
На мой взгляд тут плюсов море - нет указателей, которые могут побиться (для людей же пишите ОСь ;) ) упростится перебор задач (одно-двунаправленный список не нужен для конечного числа объектов), выкинуть/спрятать никому не нужные строки типа "process::create", "kernel::run"...
Тупо задекларировали atmos сразу со списком задач и стартанули его хоть глобально, хоть из мейна и всё завертелось - красота
Я пробовал так сделать, выгода небольшая получается (если вообще получается). Приходится инициализировать глобальные переменные, массивы, не всегда нулевыми значениями, и чем больше будет тасок, тем больше GCC нагенерит такого инициализационного кода, который будет еще до
main()выполняться, но при этом жрать программную память, потому что значения для инициализации будут храниться именно в ней. В AVR, к сожалению, нет никакой секции данных, и все глобальные или статические переменные, отличные от нуля, компилятор заполняет, когда код начинает выполняться. В итоге, вместо кучи нагенеренного кода инициализации каждой таски я делаю общую функцию, которая делает то же самое, но одинаково для всех тасок - профит. Кроме того,process::createпозволяет создавать таски динамически из других тасок, появляется возможность завершать таски и т.д.