Надеюсь, вы уже осилили толстую статью про настройку таймера и готовы переходить к новой части приключения. Если нет, то настоятельно рекомендую все же ознакомиться с первой частью этого цикла статей.
А сегодня мы будем писать на C++ односвязный список. Так как наша операционная система для AVR будет работать в крайне ограниченных по ресурсам условиях, мы будем стараться сэкономить как можно больше места и сделать код быстрее. Без какой-либо структуры данных для хранения списка запущенных (а позднее и приостановленных) задач не обойтись. Односвязный список займет мало программной памяти, потребует очень мало оперативной памяти и в целом хорошо подойдет для наших нужд. Он предельно прост, но при этом мы постараемся максимально его оптимизировать.
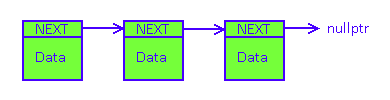
Итак, что же такое односвязный список? Как видно из картинки, это набор элементов, каждый из которых содержит некие пользовательские данные и при этом указывает на следующий за ним элемент. По сути, мы имеем цепочку из элементов, по которой можем пройтись в одном направлении (вперед) от начала до конца. Все, что нам нужно - это хранить где-то указатель на самое начало списка. Излишние расходы - это указатель на следующий элемент (который может быть нулевым, если элемент последний в списке). Для AVR это два байта оперативной памяти на задачу, не много.
Однако, не все так просто. Мы можем захотеть, чтобы наши данные содержались не в одном списке, а в нескольких сразу одновременно. Например, это может пригодиться, когда мы захотим какую-то задачу включить не только в список выполняющихся или остановленных задач, но и в список задач, которые ожидают в данный момент некоторого события. Как этого достичь?
В операционной системе FreeRTOS, которую я уже упоминал в предыдущей статье, все реализовано достаточно прямолинейно: в каждой структуре, которая хранит данные о той или иной задаче, содержится несколько вложенных структур, каждая из которых соответствует своему списку. В этих вложенных структурах имеются указатели на следующий и предыдущий элементы списка, на сам список (который хранит такие данные, как указатели на начало и на конец списка), а также на родительскую структуру задачи. В общем, очень много всего лишнего, да и работа с такой архитектурой не самая быстрая и удобная:
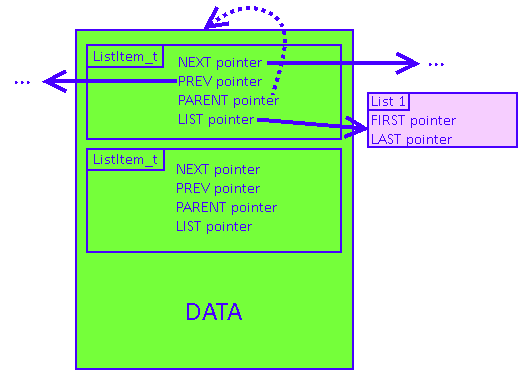
На картинке представлена структура данных задачи, которая может одновременно содержаться в двух списках сразу. FreeRTOS использует двусвязный список, но мы пока обойдемся односвязным. Вложенные структуры, содержащие данные о списках, включаются в основную структуру явно:
|
1 2 3 4 5 6 7 |
typedef struct tskTaskControlBlock { //... ListItem_t xStateListItem; ListItem_t xEventListItem; //... } tskTCB; |
Это приводит к тому, что модифицировать код становится не очень удобно. Кроме того, чтобы можно было, скажем, добавить задачу в определенный список, приходится явно передавать указатель на эту вложенную структуру в функцию, которая добавит задачу в нужный список:
|
1 |
vListInsertEnd( &xTasksWaitingTermination, &( task->xStateListItem ) ); |
Так как FreeRTOS написана на C, сам список (xTasksWaitingTermination, например, в коде выше) у нас тоже нетипизированный. Это значит, что если мы случайно перепутаем название и передадим в функцию не тот список, который хотели, то компилятор молча это проглотит, а мы потом будем ловить ошибки на этапе выполнения ОС. В идеале хотелось бы иметь что-то подобное:
|
1 |
xTasksWaitingTermination.insertEnd(task); |
В таком случае не ошибешься: какой список указал, в такой задача и добавилась, причем внутренняя структура задачи не испортилась. Так и попробуем сделать. Мы пишем на C++, а не на C, поэтому у нас в руках больше козырей. Структура нашей задачи будет выглядеть гораздо проще (по крайней мере, пока) и компактней:
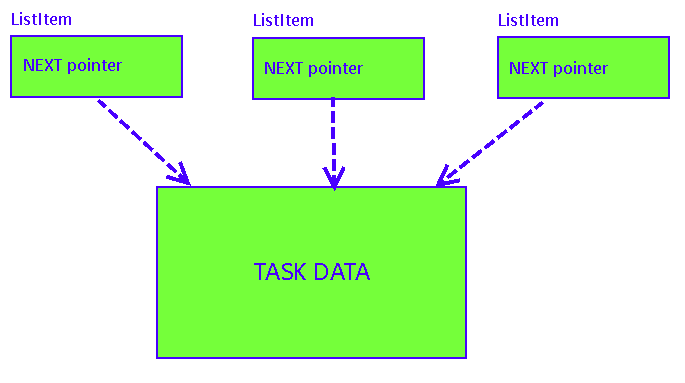
У нас будет класс задачи, который мы унаследуем от классов, каждый из которых будет представлять элемент списка. Таких классов может быть сколько угодно, потому что C++ поддерживает множественное наследование. В итоге, если мы захотим поместить задачу в один список, мы унаследуемся от одного класса-элемента списка, и это займет два дополнительных байта (размер указателя на следующий элемент списка) оперативной памяти. Если захотим иметь возможность включать задачу одновременно в два независимых списка, то унаследуемся от двух классов-элементов, и заплатим 4 байта оперативной памяти. Мы обойдемся без указателя на родительский элемент (потому что C++ и так знает, как его вычислить при таком наследовании). Мы сможем передать в функцию добавления или удаления элемента списка саму задачу, а не указатель на класс-элемент списка, а дальше C++ все разрулит самостоятельно. Если мы что-то сделаем не так, то получим ошибку компиляции. Гораздо меньше возможностей выстрелить себе в ногу.
Пора приступать к кодингу. Сначала добавим в проект вспомогательный файлик defines.h, в котором разместим определения всяких полезных макросов, которые потом будем использовать. Все эти макросы будут представлять из себя объявления различных атрибутов (для функций, классов, структур, параметров функций), которые поддерживаются компилятором GCC/G++.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
#pragma once ///Сообщить компилятору, что структура должна быть максимально упакована, ///никаких лишних байтов на выравнивание добавляться не должно. ///Необходимо для экономии памяти. #define ATMOS_PACKED __attribute__((packed)) ///Сообщить компилятору, что функция не возвращает управление вызывающему коду. ///Пригодится позже, когда будем делать ядро операционной системы. #define ATMOS_NORETURN __attribute__((noreturn)) ///Сообщить компилятору, что функция без параметров, пролога, ///эпилога и возвращаемого значения. ///Пригодится позже. #define ATMOS_NAKED __attribute__((naked)) ///Сообщить компилятору, что функция часто вызывается. ///Пригодится для содействия компилятору в оптимизации кода. #define ATMOS_HOT __attribute__((hot)) ///Сообщить компилятору, что функция редко вызывается. ///Пригодится для содействия компилятору в оптимизации кода. #define ATMOS_COLD __attribute__((cold)) ///Сообщить компилятору, что функция где-то используется. ///Иногда функция, которая используется только из ассемблерной вставки, ///компилятором может быть удалена за ненадобностью, потому что компилятор ///не понимает, что функция все же нужна. Этот макрос заставляет его ///сохранить функцию в собранном бинарнике, чтобы ее потом нашел линковщик. #define ATMOS_USED __attribute__((used)) ///Сообщить компилятору, что функция представляет из себя задачу ///операционной системы. Эта функция не сохраняет значения некоторых ///регистров, но при этом безопасна для прерываний. ///Подробнее - позже, когда перейдем к ядру. #define ATMOS_OS_TASK __attribute__((OS_task)) ///Сообщить компилятору, что функция представляет из себя главную функцию ///операционной системы. Эта функция не сохраняет значения некоторых ///регистров и небезопасна для прерываний. ///Подробнее - позже, когда перейдем к ядру. #define ATMOS_OS_MAIN __attribute__((OS_main)) ///Отметить, что конкретные параметры функции не могут иметь ///значение 0. Может применяться только к параметрам-указателям. ///Может улучшить оптимизацию кода и позволяет добавить ///некоторые проверки на этапе компиляции. #define ATMOS_NONNULL(...) __attribute__((nonnull(__VA_ARGS__))) |
Переходим к написанию кода для односвязного списка. Добавляем в проект файл forward_list.h, и поехали:
|
1 2 3 4 5 6 7 8 |
#pragma once #include "defines.h" namespace atmos { namespace container { |
Подключили заголовочный файл, который только что сделали, и объявили пространства имен. Весь код разместим в одном заголовочном файле, чтобы потом подключить этот файл в другой cpp-файл, где будет реализация ядра операционной системы. Это позволит компилятору гораздо лучше оптимизировать код, чем если бы код списка был сам по себе разбит на h- и cpp-файлы.
|
1 2 3 4 |
struct ATMOS_PACKED forward_list_element { forward_list_element* next = nullptr; }; |
Определили структуру, которая представляет из себя тот самый элемент списка. Она ничего не содержит, кроме указателя на следующий элемент списка. Этот указатель может иметь значение nullptr (0) в том случае, если этот элемент списка последний.
Мы не сможем несколько раз унаследоваться структуры forward_list_element. Компилятор выдаст ошибку о том, что мы пытаемся выполнить наследование от одного и того же класса более одного раза. Поэтому с такой структурой поместить задачу в два и более списков одновременно окажется невозможным. Этот вопрос мы решим позже.
Теперь я приведу объявление класса односвязного списка, который содержит указатель на начало списка и набор функций для работы с ним:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
struct ATMOS_PACKED forward_list_base { ///Указатель на первый элемент списка ///или nullptr, если список пуст. forward_list_element* first_element = nullptr; ///<summary>Добавить элемент в начало списка.</summary> ///<param name="elem">Элемент, который следует добавить ///в список. Не должен быть добавленным в другой список. ///Не может быть нулевым.</param> void push_front(forward_list_element* elem) ATMOS_NONNULL(1); ///<summary>Получить и удалить первый элемент ///из списка.</summary> ///<returns>Вернет первый элемент списка или ///nullptr, если список был пуст.</returns> forward_list_element* pop_front(); ///<summary>Удалить элемент из списка</summary> ///<remarks>Имеет временную сложность O(n).</remarks> ///<param name="elem">Любой элемент любого списка. ///Не может быть нулевым.</param> ///<returns>Вернет true, если элемент был удален, ///или false, если такого элемента в списке нет.</returns> bool remove(forward_list_element* elem) ATMOS_NONNULL(1); ///<summary>Вставить элемент "elem" ///перед элементом "current".</summary> ///<param name="prev">Элемент, идущий перед элементом "current". ///Может быть нулевым (nullptr).</param> ///<param name="current">Элемент, после которого ///должен быть вставлен элемент "elem". ///Не может быть нулевым.</param> ///<param name="elem">Элемент, не добавленный в другой список. ///Не может быть нулевым.</param> void insert_before(forward_list_element* prev, forward_list_element* current, forward_list_element* elem) ATMOS_NONNULL(2, 3); ///<summary>Проверить, пуст ли список.</summary> ///<returns>Вернет true, если список пуст.</returns> bool empty() const; ///<summary>Получить первый элемент списка или ///nullptr, если список пуст.</summary> forward_list_element* first(); }; |
Как вы заметили, структуры помечены макросом ATMOS_PACKED, и некоторые параметры-указатели функций, которые не могут принимать нулевое значение, отмечены макросом ATMOS_NONNULL, в который мы передаем номера соответствующих параметров. Это все нужно для более эффективных оптимизаций и экономии места.
Теперь у нас есть базовый класс элемента списка и класс самого списка. Мы можем добавить элемент в начало списка, удалить элемент из начала списка, получить первый элемент списка, проверить, пуст ли список. Все эти операции будут выполняться очень быстро, независимо от того, сколько у нас в целом элементов в этом списке. Можно удалить элемент из произвольного места списка, но эта операция будет выполняться тем дольше, чем больше у нас элементов. Это особенность односвязного списка: нам придется пройтись по всем элементам, пока мы не найдем нужный, чтобы его удалить. В двусвязном списке скорость выполнения этой операции не зависела бы от количества элементов, но зато мы бы потратили больше оперативной памяти. Так как задач у нас будет, скорее всего, немного, удалять задачу из списка даже с десятком элементов будет не так долго. Помимо прочих, у нас есть также функция добавления элемента перед другим.
Я не буду приводить здесь реализацию методов этого класса, потому что она достаточно проста. Можете посмотреть ее в исходниках на GitHub [TODO] или скачать готовый проект в конце статьи.
Остается один главный вопрос: как нам эти классы позволят включить одну задачу одновременно в несколько списков? Правильно, никак. С их помощью мы сможем поместить задачу только в один список. Поэтому мы сделаем следующий финт: мы напишем шаблонных наследников для этих двух классов. Эти шаблоны мы сможем специфицировать уникальным образом для каждого списка. Можно было бы сразу сделать эти классы шаблонными, но тогда мы бы при создании каждого списка теряли много программной памяти. GCC не умеет объединять код функций, сгенерированных из шаблонов, специфицированных разными параметрами, даже если код этих функций полностью идентичен. Поэтому пришлось выполнить эту работу за него и вынести общий код в нешаблонный класс.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
///Шаблонный наследник класса элемента списка. ///Мы будем специфицировать его уникальным тэгом, ///соответствующим конкретному списку. Также параметром ///шаблона является тип, который будет содержаться в списке. template<typename Tag, typename ContainedType> struct ATMOS_PACKED forward_list_element_tagged : forward_list_element { using tag_type = Tag; using contained_type = ContainedType; using list_element_type = forward_list_element_tagged<tag_type, contained_type>; ///<summary>Преобразует элемент списка в тип, который ///содержится в списке.</summary> ///<returns>Вернет указатель на элемент, который ///содержится в списке.</returns> contained_type* operator->() { return static_cast<contained_type*>(this); } }; |
Теперь у нас есть возможность задать уникальный тег, который будет идентифицировать конкретный список. Кроме того, так как класс элемента списка теперь шаблонный, мы можем в полной мере воспользоваться множественным наследованием, чтобы включить задачу в несколько списков одновременно. Но нам нужен еще класс самого списка, который будет уметь работать с такими шаблонными элементами.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
///Типизированный односвязный список, который ///может работать с шаблонами forward_list_element_tagged. template<typename ForwardListElement> struct ATMOS_PACKED forward_list_tagged : private forward_list_base { using list_element_type = ForwardListElement; using tag_type = typename list_element_type::tag_type; using contained_type = typename list_element_type::contained_type; ///Метод empty возьмем из базового класса. using forward_list_base::empty; ///<summary>Добавить элемент в начало списка.</summary> ///<param name="elem">Элемент, не содержащийся в других ///списках с таким же тегом. Не должен быть nullptr.</param> void push_front(list_element_type* elem) ATMOS_NONNULL(1); ///<summary>Извлечь первый элемент списка и ///удалить его из списка.</summary> ///<returns>Вернет указатель на первый элемент списка ///или nullptr, если список пуст.</returns> list_element_type* pop_front(); ///<summary>Удалить элемент из списка.</summary> ///<remarks>Имеет временную сложность O(n).</remarks> ///<param name="elem">Любой элемент любого списка. ///Не может быть нулевым.</param> ///<returns>Вернет true, если элемент был удален, ///или false, если такого элемента в списке нет.</returns> bool remove(list_element_type* elem) ATMOS_NONNULL(1); ///<summary>Получить первый элемент списка или ///nullptr, если список пуст.</summary> list_element_type* first(); ///<summary>Вставить элемент "elem" перед тем элементом, ///который удовлетворяет заданному условию.</summary> ///<remarks>Если список пуст, то "elem" просто добавляется ///в список.</remarks> ///<param name="elem">Элемент, не добавленный в другой список ///того же типа. Не может быть nullptr.</param> ///<param name="compare">Функтор "compare" должен возвращать ///true, если элемент списка удовлетворяет условию, ///или false в противном случае. Этот функтор будет ///вызываться для каждого элемента в списке и ///принимать в качестве параметра указатель на текущий ///элемент списка.</param> template<typename Func> void insert_before(list_element_type* elem, Func&& compare) ATMOS_NONNULL(1); ///<summary>Возвращает элемент, следующий за элементом "elem".</summary> ///<param name="elem">Любой элемент любого списка. ///Не может быть nullptr.</param> ///<returns>Вернет элемент, следующий за элементом "elem" ///либо nullptr, если это последний элемент в списке.</returns> static list_element_type* next(list_element_type* elem) ATMOS_NONNULL(1); }; |
В этом классе, который мы унаследовали от forward_list_base, содержатся те же функции, что и в базовом классе, но мы сделали их типизированными. Они будут принимать на вход указатель на структуру задачи и сами определять, какой из указателей next базового класса forward_list_element использовать. Если мы в какой-то из методов передадим класс, не унаследованный от класса forward_list_element_tagged с таким же тегом, как у списка, мы получим ошибку компиляции.
Я не делал константные перегрузки методов и не добавлял лишних проверок. Это все остутствует для экономии места и ускорения работы кода. Реализацию методов я снова опущу, но скажу, что они по большей части представляют из себя вызовы одноименных методов базового класса с соответствующим преобразованием типов.
Взглянем, как это все можно использовать. Я сделал тестовый проект для Visual Studio 2015 (ссылка есть в конце статьи), где применяется наш список для иллюстрации работы с ним. Я приведу кусок кода с комментариями здесь:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 |
#include <iostream> #include "forward_list.h" //Задаем теги для разных списков. //Этот - для списка спящих собак. struct sleeping_dog_list_tag; //Этот - для списка черных собак. struct black_dog_list_tag; //Этот - для списка красных котов. struct red_cat_list_tag; //Структура "собака". struct doge; //Структура "кот". struct cat; //Определяем типы элементов каждого списка. using sleeping_dog_list_element = atmos::container::forward_list_element_tagged<sleeping_dog_list_tag, doge>; using black_dog_list_element = atmos::container::forward_list_element_tagged<black_dog_list_tag, doge>; using red_cat_list_element = atmos::container::forward_list_element_tagged<red_cat_list_tag, cat>; //Определяем типы каждого списка. using sleeping_dog_list = atmos::container::forward_list_tagged<sleeping_dog_list_element>; using black_dog_list = atmos::container::forward_list_tagged<black_dog_list_element>; using red_cat_list = atmos::container::forward_list_tagged<red_cat_list_element>; //Определение структуры "собака". //Собака может быть спящей, черной, //либо и то и другое одновременно. //Обратите внимание, что собака не //может быть красным котом! :) //Мы не унаследовались от red_cat_list_element. struct doge : sleeping_dog_list_element, black_dog_list_element { doge(const char* name) noexcept : name(name) { } //Имя собаки. const char* name; }; //Список спящих собак. sleeping_dog_list sleeping_dogs; //Список черных собак. black_dog_list black_dogs; //Список красных котов. red_cat_list red_cats; //Функция печати содержимого любого списка. template<typename List> void print_list(List& list) { auto current = list.first(); const char* comma = ""; while (current) { std::cout << comma; comma = ", "; std::cout << (*current)->name; current = List::next(current); } } //Функция печати списков собак. void print_dogs() { std::cout << "Sleeping dogs: "; print_list(sleeping_dogs); std::cout << std::endl << "Black dogs: "; print_list(black_dogs); std::cout << std::endl; } int main() { //Создадим пять собак с разными именами. doge dogs[5]{ "Buster", "Shawn1x", "Roxy", "Ginger", "Ruby" }; //Первые три будут спать. sleeping_dogs.push_front(&dogs[0]); sleeping_dogs.push_front(&dogs[1]); sleeping_dogs.push_front(&dogs[2]); //Посдение три будут черными. black_dogs.push_front(&dogs[2]); black_dogs.push_front(&dogs[3]); black_dogs.push_front(&dogs[4]); //Эта строка не скомпилируется! Собака не может быть //в списке котов! C++ выполняет эту проверку за нас. //red_cats.push_front(&dogs[0]); //Выводим содержимое списков собак. print_dogs(); //Добавим теперь еще и Ruby в список //спящих собак. std::cout << std::endl << dogs[4].name << " is now sleeping, too!" << std::endl; sleeping_dogs.push_front(&dogs[4]); //А Ginger удаляем из списка черных собак. std::cout << dogs[3].name << " is not black anymore!" << std::endl; black_dogs.remove(&dogs[3]); //Это тоже не скомпилируется! //Shawn1x - собака, и не может быть //в списке котов! :D //red_cats.remove(&dogs[1]); //Выводим содержимое списков собак. print_dogs(); } |
Выведет эта программа следующее:
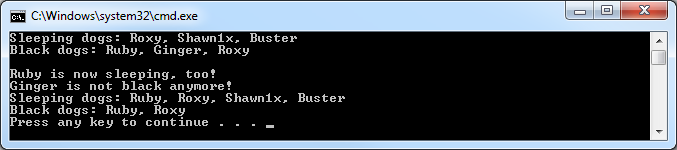
Все выглядит достаточно элегантно. Компилятор выдаст ошибку, если мы попытаемся добавить элемент в тот список, который не должен содержать его. Как в примере выше: класс doge унаследован от sleeping_dog_list_element и black_dog_list_element, но не от red_cat_list_element. Поэтому, если мы попытаемся добавить элемент типа doge в список котов (или удалить его оттуда), то получим ошибку на этапе компиляции, что предотвратит ошибку в программе. Давайте еще посмотрим на иерархию классов в этом проекте:
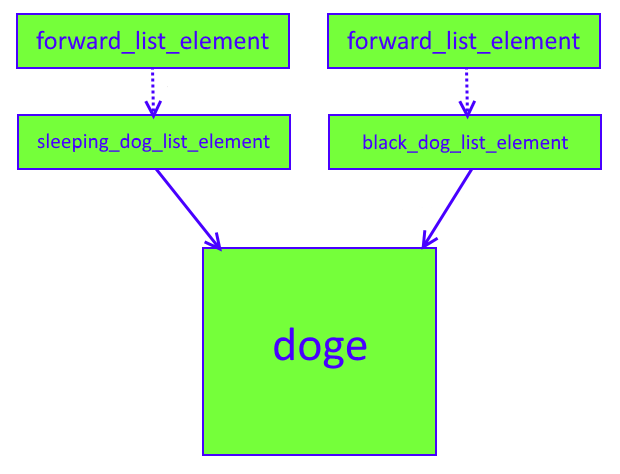
На этом на сегодня все. Как обычно, вы можете лицезреть развитие проекта на GitHub и скачать код проекта atmos полностью. Также, по доступен тестовый проект для Visual Studio (про собак и котов).
Спасибо большое за статьи, надеюсь их будет побольше <3.
Оффтоп: подскажите, пожалуйста, как можно запустить программу из оперативки не выгружая на хард? Куда копать?
Я когда-то пробовал загружать DLL из памяти, не выгружая на хард. В DllMain можно написать любой код, который будет выполняться. На эту тему есть много статей, вот, например: https://www.joachim-bauch.de/tutorials/loading-a-dll-from-memory/, или вот это тоже подойдет: https://forum.antichat.com/threads/132116/. Вот это еще можно пробовать: https://stackoverflow.com/questions/305203/createprocess-from-memory-buffer
Но это все, конечно же, хаки, и не гарантируют работоспособности с произвольными бинарниками.