Здарова, щеглы, сегодня мы своими руками будем писать скрипт на Python. Нам понадобятся: интерпретатор Python 3 под "какая-там-у-вас-ОС", текстовый редактор с подсветкой синтаксиса, например, Sublime Text, Google, упаковка прамирацетама, бутылка минеральной воды и 60 минут свободного времени.
Перед тем как писать скрипт, мы должны определиться, что он вообще будет делать. Делать он будет следующее: получив на вход домен и диапазон IP-адресов, многопоточно проходить список этих адресов, совершать HTTP-запрос к каждому, в попытках понять, на каком же из них размещен искомый домен. Зачем это нужно? Бывают ситуации, когда IP-адрес домена закрыт Cloudflare, или Stormwall, или Incapsula, или еще чем-нибудь, WHOIS история не выдает ничего интересного, в DNS-записях такая же канитель, а, внезапно, один из поддоменов ресолвится в адрес из некоторой подсети, которая не принадлежит сервису защиты. И в этот момент нам становится интересно, вдруг и основной домен размещен в той же самой подсети.
Погнали, сразу выпиваем половину бутылки воды, и пишем следующий код:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 |
import argparse import logging import coloredlogs import ssl import concurrent.futures import urllib.request from netaddr import IPNetwork from collections import deque VERSION = 0.1 def setup_args(): parser = argparse.ArgumentParser( description = 'Domain Seeker v' + str(VERSION) + ' (c) Kaimi (kaimi.io)', epilog = '', formatter_class = argparse.ArgumentDefaultsHelpFormatter ) parser.add_argument( '-d', '--domains', help = 'Domain list to discover', type = str, required = True ) parser.add_argument( '-i', '--ips', help = 'IP list (ranges) to scan for domains', type = str, required = True ) parser.add_argument( '--https', help = 'Check HTTPS in addition to HTTP', action = 'store_true' ) parser.add_argument( '--codes', help = 'HTTP-codes list that will be considered as good', type = str, default = '200,301,302,401,403' ) parser.add_argument( '--separator', help = 'IP/Domain/HTTP-codes list separator', type = str, default = ',' ) parser.add_argument( '--include', help = 'Show results containing provided string', type = str ) parser.add_argument( '--exclude', help = 'Hide results containing provided string', type = str ) parser.add_argument( '--agent', help = 'User-Agent value for HTTP-requests', type = str, default = 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1' ) parser.add_argument( '--http-port', help = 'HTTP port', type = int, default = 80 ) parser.add_argument( '--https-port', help = 'HTTPS port', type = int, default = 443 ) parser.add_argument( '--timeout', help = 'HTTP-request timeout', type = int, default = 5 ) parser.add_argument( '--threads', help = 'Number of threads', type = int, default = 2 ) args = parser.parse_args() return args if __name__ == '__main__': main() |
Ни одного комментария, какие-то import, непонятные аргументы командной строки и еще эти две последние строчки... Но будьте спокойны, все нормально, это я вам как мастер программирования на Python с 30-минутным стажем говорю. Тем более, как известно, Google не врет, а официальная документация по Python - это вообще неоспоримая истина.
Так что же мы все-таки сделали в вышеописанном фрагменте кода? Мы подключили модули для работы с аргументами коммандной строки, модули для логирования (потокобезопасные между прочим!), модуль для работы с SSL (для одной мелочи, связанной с HTTPS-запросами), модуль для создания пула потоков, и, наконец, модули для совершения HTTP-запросов, работы с IP-адресами и двухсторонней очередью (по поводу различных типов импорта можно почитать здесь).
После этого мы, в соответствии с документацией по модулю argparse, создали вспомогательную функцию, которая будет обрабатывать аргументы, переданные скрипту при запуске из командной строки. Как видите, в скрипте будет предусмотрена работа со списком доменов/IP-диапазонов, а также возможность фильтрации результатов по ключевым словам и по кодам состояния HTTP и еще пара мелочей, как, например, смена User-Agent и опциональная проверка HTTPS-версии искомого ресурса. Последние две строки в основном используются для разделения кода, который будет выполнен при запуске самого скрипта и при импортировании в другой скрипт. В общем тут все сложно, все так пишут. Мы тоже так будем писать. Можно было бы немного модифицировать этот код, например, добавив возврат разных статусов системе в зависимости от того, как отработала функция main, добавить argv в качестве аргумента, и так далее, но мы изучаем Python только 10 минут и ленимся вчитываться в документацию.
Делаем перерыв и выпиваем глоток освежающей минеральной воды.
Поехали дальше.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
def main(): # Обрабатываем аргументы и инициализируем логирование # с блекджеком и цветными записями args = setup_args() coloredlogs.install() # Сообщаем бесполезную информацию, а также запускаем цикл проверки logging.info("Starting...") try: check_loop(args) except Exception as exception: logging.error(exception) logging.info("Finished") def check_loop(args): # Создаем пул потоков, еще немного обрабатываем переданные аргументы # и формируем очередь заданий with concurrent.futures.ThreadPoolExecutor(max_workers = args.threads) as pool: domains = args.domains.split(args.separator) ips = args.ips.split(args.separator) codes = args.codes.split(args.separator) tasks = deque([]) for entry in ips: ip_list = IPNetwork(entry) for ip in ip_list: for domain in domains: tasks.append( pool.submit( check_ip, domain, ip, args, codes ) ) # Обрабатываем результаты и выводим найденные пары домен-IP for task in concurrent.futures.as_completed(tasks): try: result = task.result() except Exception as exception: logging.error(exception) else: if result != None: data = str(result[0]) if( ( args.exclude == None and args.include == None ) or ( args.exclude and args.exclude not in data ) or ( args.include and args.include in data ) ): logging.critical("[+] " + args.separator.join(result[1:])) |
В коде появился минимум комментариев. Это прогресс. Надо войти в кураж (не зря мы заготовили прамирацетам) и дописать одну единственную функцию, которая будет осуществлять, непосредственно, проверку. Ее имя уже упомянуто в коде выше: check_ip.
30 минут спустя
Хорошо-то как. Не зря я говорил, что понадобится час времени. Продолжим.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
def check_ip(domain, ip, args, codes): # Преобразуем IP из числа в строку # Магическая code-flow переменная для совершения двух проверок # И бесполезное логирование ip = str(ip) check_https = False logging.info("Checking " + args.separator.join([ip, domain])) while True: # Задаем порт и схему для запроса в зависимости от магической переменной schema = 'https://' if check_https else 'http://'; port = str(args.https_port) if check_https else str(args.http_port) request = urllib.request.Request( schema + ip + ':' + port + '/', data = None, headers = { 'User-Agent': args.agent, 'Host': domain } ) # Совершаем запрос, и если получаем удовлетворительный код состояни HTTP, # то возвращаем содержимое ответа сервера, а также домен и IP try: response = urllib.request.urlopen( request, data = None, timeout = args.timeout, context = ssl._create_unverified_context() ) data = response.read() return [data, ip, domain] except urllib.error.HTTPError as exception: if str(exception.code) in codes: data = exception.fp.read() return [data, ip, domain] except Exception: pass if args.https and not check_https: check_https = True continue return None |
В общем-то весь наш скрипт готов. Приступаем к тестированию.
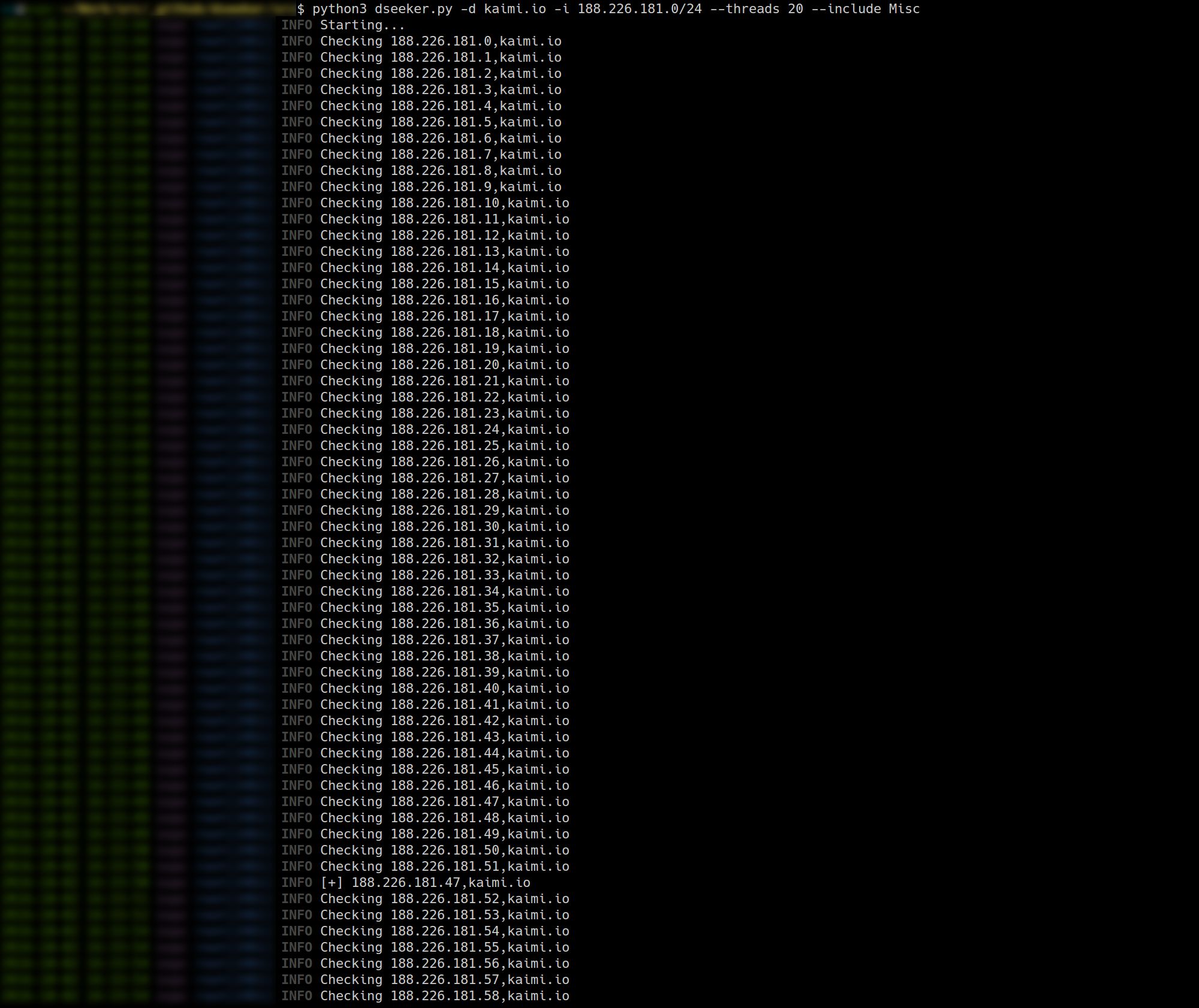
Неожиданно узнаем, что у блога есть альтернативный IP-адрес. И действительно:
|
1 |
curl -i 'http://188.226.181.47/' --header 'Host: kaimi.io' |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
HTTP/1.1 301 Moved Permanently Server: nginx/1.4.6 (Ubuntu) Date: Sun, 02 Oct 2016 13:52:43 GMT Content-Type: text/html Content-Length: 193 Connection: keep-alive Location: https://kaimi.io/ <html> <head><title>301 Moved Permanently</title></head> <body bgcolor="white"> <center><h1>301 Moved Permanently</h1></center> <hr><center>nginx/1.4.6 (Ubuntu)</center> </body> </html> |
Однако:
|
1 |
curl -i 'https://188.226.181.47/' --header 'Host: kaimi.io' |
|
1 |
curl: (51) SSL: certificate subject name (*.polygraph.io) does not match target host name '188.226.181.47' |
Какой-то левый хост обрабатывает запросы. Почему? Потому что это прокси, который реагирует на содержимое заголовка Host. В общем скрипт готов, по крайней мере альфа-версия скрипта. Если вам понравилось - подписывайтесь, ставьте лайки, шлите pull-реквесты на github.
Щеглы...
Старый дизайн сайта был более трЪ!
Новый читабельный, но какой-то не родной.
Новый на планшетах-смартфонах читается получше, плюс тема почище
Кайми это же не перл.
Всякое случается...
Привет, твоя программа а точнее сылка на нее не работает, можешь перезалить? mytsetxprohelper
Поправил
Это конечно совсем не то место, но хз, чета других контактов не нашел. Ваш квест #3 не работает. Говорит сервак не доступен. Я даже хз сколько времени прошло с релиза, но я бы хотел поиграть. И еще, интересно, что за приз был в архиве от первого квеста?
Да, на новый домен переехали, а квест пофиксить забыли :)
Спасибо, исправим в ближайшее время.
Про подарок в первом квесте, может быть, Kaimi помнит еще, я уже забыл.
Не JS-обфускатор?
Да, точно, он был вроде как.
Исправили, третий квест теперь должен работать.
"Здарова, щеглы"
Ну если мы - щеглы, тогда ты - мерзкий земляной червяк.
Похоже, кто-то не в теме +)
Чувак! Ты лучший учитель на свете!