Всем привет, это dx (нет, это не Kaimi притворяется, это настоящий dx)! Сегодня мы поговорим об одном из частых программных багов, который регулярно приводит к уязвимостям, - гонках. Я не эксперт в их эксплуатации (в отличие от Kaimi, который, может быть, когда-нибудь поделится с вами хорошими примерами из своего опыта, а также современными методами и инструментами). Я же поделюсь знаниями с другой стороны баррикады, и расскажу, что такое гонки с точки зрения ПО, и какие факторы могут помочь "выиграть" при их эксплуатации.
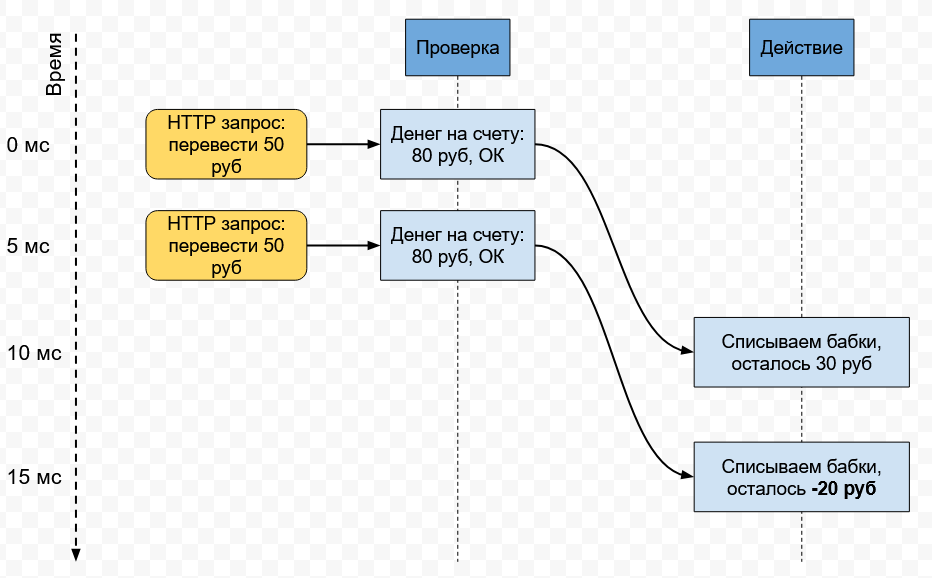
Один из частых типов гонок (race condition) - это Time-of-Check Time-of-Use (TOCTOU, CWE-367). Действительно, часто логика программы или веб-сервиса представляет из себя проверку данных с последущюим использованием результата этой проверки, в то время как результат мог поменяться между этими двумя операциями. Простейший пример: почти одновременно вы отправляете на сервер банка два HTTPS-запроса с требованием перевести 50 рублей с вашего счёта на другой счёт. При этом ваш баланс - 80 рублей. Если реализация логики со стороны банка некорректная, то оба запроса получат одобрение на процессинг (оба запроса сначала увидят, что 50 < 80, а затем оба будут обработаны), и ваш баланс уйдёт в минус. Это нарушение целостности (integrity) системы. И проверка, и исполнение запроса должны быть выполнены атомарно, чтобы целостность не нарушалась.
Иногда гонки принимают более сложные формы. Например, вы пентестите ресурсы крупной компании, сервера которой находятся в нескольких независимых дата-центрах по стране или даже миру. Сохранить целостность и консистентность данных в таких условиях гораздо сложнее, потому что вычисления и хранение данных становятся распределёнными. В любой момент, какой-то из серверов может оказаться недоступным, перегруженным, или совсем сломаться. Один дата-центр может оказаться отрезанным хуситами от другого. И чем больше серверов у компании, тем больше вероятность такого события. Даже при использовании готовых проверенных систем хранения данных, легко допустить ошибки в их настройке, или не учесть что-то при комбинировании нескольких систем. Реальные компании комбинируют десятки систем (открытых, платных и самописных) - баз данных, кешей, очередей событий (stream / batch processing), и систем управления всем этим делом. Настроить все эти системы, чтобы они корректно и без сбоев работали совместно, очень сложно.
Например, один сервер может считать, что данные, которые им были отправлены в БД, гарантированно сохранены, но в результате ошибок в ПО или некорректной настройки, при удачном (или неудачном, смотря с какой стороны оценивать) стечении обстоятельств, данные в базе оказываются утеряны. Это приводит к рассогласованию системы: один сервер получил подтверждение от БД, что данные точно сохранены, но на деле это не так. Такие проблемы, как проверка уникальности или других строгих инвариантов (например, запрет регистрировать несколько аккаунтов на один адрес e-mail, или запрет списывать больше денег со счёта, чем там имеется), а также транзакции в целом, в распределённых системах требуют консенсуса, который чрезвычайно сложно правильно реализовать.
Гонки на одном сервере
Посмотрим сначала на более просто случай гонок: когда баг находится в коде бизнес-логики сервиса, обрабатывающего запросы, и вы можете непосредственно его проэксплуатировать.
Какие могут быть последствия у таких гонок?
- Повреждение памяти процесса, что может привести к порче данных не только вашего запроса, но и запросов других пользователей. В лучшем случае это вызовет падение сервиса (denial of service, DoS) и потере данных других пользователей, запросы которых обрабатывал этот сервис в момент падения. В худшем - к записи невалидных испорченных данных в хранилища.
- Нарушение инварианта в результате того, что то действие, которое должно было выполниться единожны, выполняется несколько раз. Например, как я уже упоминал выше, вы дважды списываете деньги со счёта, на котором их недостаточно. Как правило, последствия этого будут видны сразу, прямо в ответе от сервиса, к которому вы послали запрос.
Как увеличить вероятность поймать такую гонку?
- Предварительно нагрузить сервер, отправляя больше запросов, не имеющих отношения к гонке. Это может дать целевым запросам больше времени между моментом проверки и моментом исполнения.
- Послать одновременно большое количество конфликтующих запросов к сервису. Можно даже отправить N запросов вплоть до последнего байта, и когда все тела всех запросов будут отправлены, одновременно дослать и их последние байты, чтобы заставить сервер начать обрабатывать эти запросы практически одновременно. Такая методика называется Last-Byte Synchronization.
- Слать много запросов подряд в несколько открытых подключений к серверу, чтобы сервер обрабатывал их как можно ближе друг к другу во времени.
- Учтите, что перед сервисом может находиться балансировщик нагрузки, который ваши запросы будет направлять к разным серверам. Это может усложнить (или в некоторых случаях наоборот упростить) эксплуатацию гонки.
Распределённые гонки и нарушения инвариантов
Гораздо сложнее проэксплуаровать гонки, которые могут возникнуть где-то на более глубоком уровне, позже непосредственной отправки запросов, вызвав рассогласование между несколькими серверами или компонентами системы. Обнаружить последствия таких гонок тоже сложнее. В этом случае мы подразумеваем, что в бизнес-логике сервиса, принимающего начальный запрос, ошибок нет, но есть проблемы с конфигурацией сервисов внутри системы или ошибки в настройках БД, кешей, или же баги при использовании этих сервисов.
Представим такой упрощённый и выдуманный пример. Вы хотите поучаствовать в беспроигрышной всероссийской лотерее с крупными призами, но зарегистрироваться можно только один раз с вашими паспортными данными. Гонок в коде самого сервиса нет. Предположим, что верхнеуровневая архитектура сервиса лотереи выглядит так:
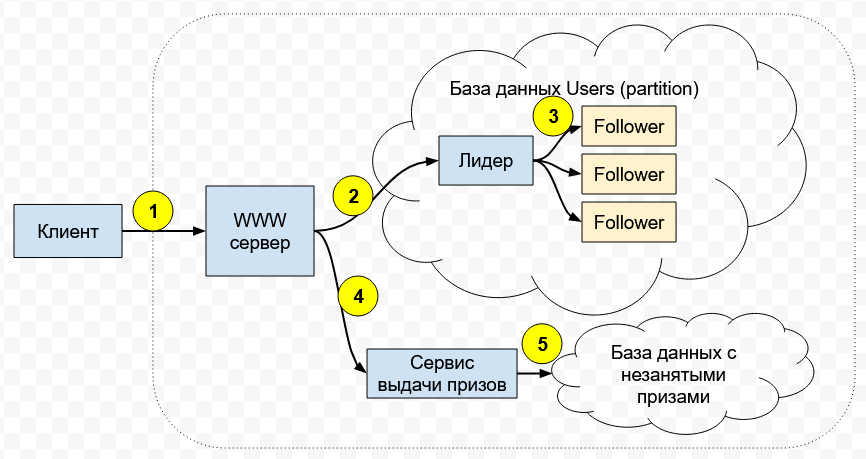
- Вы подключаетесь к сервису и отправляете запрос на регистрацию
(1). - Ваш запрос обслуживает WWW-сервер, который отсылает ваши данные в БД
(2). Если там уже есть такие данные (то есть вы уже зарегистрировались раньше), то база не даст их записать, и вы получите ошибку. Это реализовано через транзакции и атомарно, то есть программной гонки как таковой нет. - База данных распределённая: она разделена на части (называются partitions или shards), каждая из которых хранит данные только о части пользователей. Плюс, каждый partition имеет несколько реплик
(3)в конфигурации с одним лидером: лидер принимает запросы на запись, а потом реплицирует их на несколько дополнительных серверов для надёжности. - Если WWW-сервер получает от базы положительный результат (данные были уникальны и теперь записаны в БД), WWW-сервер обращается к отдельному сервису выдачи призов
(4), который достаёт из базы призов случайный незанятый приз(5)и сообщает о выигрыше клиенту. - При повторной попытке регистрации с теми же данными, когда WWW-сервер отправит данные в БД, он получит ответ о том, что пользователь уже имеется в базе. К сервису выдачи призов после этого WWW-сервер обращаться не будет, а клиент получит ответ о том, что он свой приз уже забрал.
В этой архитектуре есть и другие проблемы, но мы сосредоточимся на гонках, нарушающих целостность данных. Допустим, вы шлёте запрос addUserToLottery со своими уникальными данными, которые ещё не были зарегистрированы ранее. База данных настроена с ошибками, или является очередной новой модной базой данных, в коде которой есть баги. Она отправляет на WWW-сервер подтверждение о том, что транзакция выполнена, когда на деле данные ещё не зареплицировались на достаточное количество реплик, и могут быть утеряны в случае возникновения нештатных ситуаций.
В этот момент, лидер базы данных падает или становится отрезанным от остальной сети. Через какое-то время, остальные сервера БД с помощью криво реализованного консенсуса выбирают другого лидера, и транзакция с добавлением ваших данных теряется, потому что данные имелись только на утерянном старом лидере.
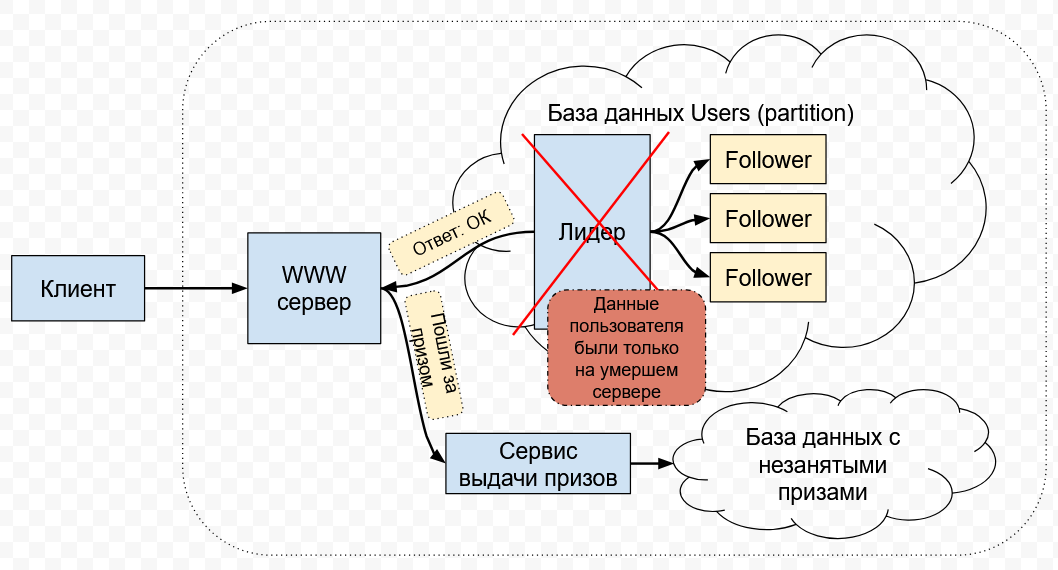
WWW-сервер же в этот момент уже точно уверен, что ваши паспортные данные были гарантированно сохранены, - ведь БД возвратила положительный ответ! WWW-сервер обращается к сервису выдачи призов, чтобы сообщить вам об успешной регистрации в лотерее и о вашем мгновенном выигрыше.
Клиент же получает возможность зарегистрироваться с теми же паспортными данными повторно и получить второй приз.
Думаете, это крайне маловероятная проблема? Да, такие баги действительно встречаются реже, и поймать их сложнее. Но с ними регулярно сталкивались и сталкиваются все компании с распределёнными серверными архитектурами. Представьте, что вместо одной-двух баз данных их у компании 500, и поверх них навёрнуты кеши, есть очереди обработки сообщений, балансировщики нагрузки, менеджеры, и всё это связано друг с другом кастомным кодом. Всё это использует массу языков программирования и технологий. Есть ещё админы, которые это всё обслуживают и тоже регулярно делают ошибки.
Итак, какие последствия у подобных проблем?
- Потеря данных и нарушение целостности системы: когда часть серверов считает, что данные сохранены, а другая часть эти данные потеряла. В результате, вы получаете возможность выполнить какое-то уникальное действие повторно, или меняете что-то в системе незаметно, или даже получаете доступ к данным других пользователей. У GitHub достаточно давно случился инцидент, когда MySQL кластер выбрал в качестве нового лидера сервер с устаревшими данными, в результате часть данных была потеряна. Кластер использовался исплючительно для генерирования уникальных id (колонка
AUTO_INCREMENT). В итоге, после передачи лидерства, часть id были выданы повторно. Целостность нарушилась: id в системе перестали быть уникальными. Пользователи получили доступ к данным других пользователей с совпадающими id.
Как ловить такие проблемы?
- Заранее подготовьте большой набор запросов, с помощью которых вы будете проводить тестирование. Эксплуатировать распределённые гонки бывает проще в удачные моменты времени, которые я перчислю дальше. Стоит заранее подготовиться к таком моменту и максимально быстро начать тестирование при его наступлении, не тратя много времени на подготовку.
- Вы необязательно увидите результат своей атаки сразу. Могут нарушиться внутренние инварианты в системе, и заметите вы это не сразу в ответе от сервера, к которому обращаетесь. Думайте о том, что может быть нарушено внутри системы, о том, как это обнаружить с вашей позиции, и в целом будьте внимательны.
Можно ли увеличить вероятность проявления таких гонок?
- Проводите эксплуатацию в разное время дня и ночи. В зависимости от локации дата-центров компании, один или другой дата-центр может быть нагружен больше в определённое время (peak time). Например, когда в Европе с утра все проснулись и полезли читать новости за чашкой кофе, новостные ресурсы будут нагружены сильнее всего. В момент проведения чемпионата по футболу сайты, отобращающие ход матча и счёт, будут сильно загружены. В момент выборов в США будут загружены политические форумы.
- Пробуйте отсылать конфликтующие запросы к разным серверам и разным дата-центрам одновременно. Если дата-центры некорректно синхронизируют данные между собой, то поймать гонку будет проще, отправив два запроса, нарушающих целостность, к разным серверам разных дата-центров. Кроме того, часто консенсус и транзакции опираются на единое точное время, которое достаточно сложно синхронизировать внутри дата-центров, и особенно между ними. Гугл может себе позволить атомные и GPS-часы в дата-центрах, но компании поменьше не будут так заморачиваться.
- Пробуйте атаки в то время, когда компания отключает часть серверов или целый дата-центр для обслуживания (а потом включает обратно). Вы можете об этом не знать явно, но можете заметить, что часть IP-адресов перестала быть доступной. Если IP-адреса продолжают быть доступными, это в целом тоже не значит, что дата-центр, который их обычно обслуживает, доступен. Балансировщик нагрузки может перенаправлять ваши запросы к этим адресам на другие альтернативные (и более удалённые от вас) дата-центры. Вы можете об этом узнать по времени ответа на запрос: если оно в среднем выросло на фиксированное количество миллисекунд, значит, ваши запросы идут не туда, куда обычно. Компании регулярно отключают целые дата-центры для обновления оборудования, или отключают дата-центры от траффика с целью проверить устройчивость системы в целом (это называется disaster recovery). В такие моменты вероятность поймать проблемы может быть выше (особенно если в обслуживании дата-центра участвуют люди, которые совершают ошибки).
- Компании могут регулярно обновлять своё ПО на серверах. Для этого они могут отключать целый дата-центр целиком, или же использовать rolling update - когда за раз обновляется и перезагружается небольшой процент всех серверов. Такие обновления чаще всего происходят по рабочим дням примерно в одно и то же время. Если ПО написано криво, и есть незамеченные разработчиками несовместимости между старой и новой версией, то есть шанс поймать баги, проводя тестирование прямо во время rolling update. Обновление ПО БД также может вызвать смену лидера в кластере, и это тоже хорошее время ловить гонки.
- Замерять время выполнения запросов может быть полезно. Если оно резко уменьшилось или наоборот возросло с изменением тела запроса, это может означать, что что-то в системе работает нештатно.
- Отсылайте нестандартные запросы. Валидные, но, например, огромного размера, или с необычными значениями полей. Если начальный сервер, на который вы отсылаете запрос, принял и обработал его, и вы получили положительный ответ, это не значит, что то же самое успешно сделают другие сервера, которым ваш запрос (возможно, после некоторых преобразований) перешлёт первый сервер.
- Если вам удалось поймать момент, когда часть серверов или сервисов компании стала недоступна из-за внутренних проблем (да, мы все помним новости в стиле "Telegram упал, работает ли у вас?"), - это тоже хороший момент для старта тестов.
- Если есть возможность, проводите тесты также в момент изменения временных зон и часов. Например, когда переводят время в регионе дата-центров компании на летнее или наоборот. Или когда к времени добавляется дополнительная секунда. Если какие-то части системы неправильно обрабатывают подобные изменения времени, вероятность поймать гонки значительно возрастает.
Советы из списка выше могут помочь и в эксплуатации более простых гонок в бизнес-логике конкретных серверов компании. Если вы не можете нарушить целостность данных на конкретном сервере при отправке конфликтующих запросов, стоит попробовать опции из списка и, возможно, вам повезёт больше.
Это всё, что я сегодня могу рассказать про гонки. Надеюсь, статья окажется полезной на практике или, как минимум, даст вам новые знания. Удачи в эксплуатации!
